Home >> 【GPT】vicuna-33b-v1.3 部署测试
【GPT】vicuna-33b-v1.3 部署测试
2023-07-13 14:18 AtmosphereMao
vicuna-33b-v1.3
一、vicuna-33b-v1.3
-
大小约:63.5GB 二、部署测试
- 环境
- GPU:V100-32GB(32GB) * 1
- CPU:10 vCPU Intel Xeon Processor (Skylake, IBRS)
- 内存:72GB
- 部署过程
# 下载vicuna-33b-v1.3
git lfs install
git clone https://huggingface.co/lmsys/lmsys/vicuna-33b-v1.3
cd vicuna-33b-v1.3
git lfs pull
# 启动控制器
python -m fastchat.serve.controller --host 0.0.0.0
# 启动 model worker
python -m fastchat.serve.model\_worker --model-path /root/autodl-tmp/fastchat/vicuna-33b-v1.3 --host 0.0.0.0
# 8bit 使用 && cpu卸载
python -m fastchat.serve.model\_worker --model-path /root/autodl-tmp/fastchat/vicuna-33b-v1.3 --load-8bit --cpu-offloading --host 0.0.0.0
# 最后启动webserver
python -m fastchat.serve.gradio\_web\_server --port 6006
# openai api 启动
python3 -m fastchat.serve.openai\_api\_server --host 0.0.0.0 --port 8001
2. model启动测试
2.1 正常运行测试
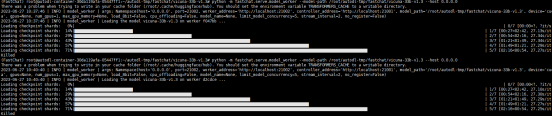
内存不足,无法加载model
- CPU
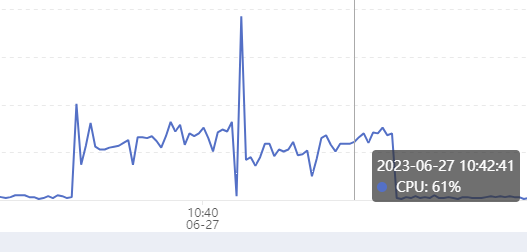
- 内存
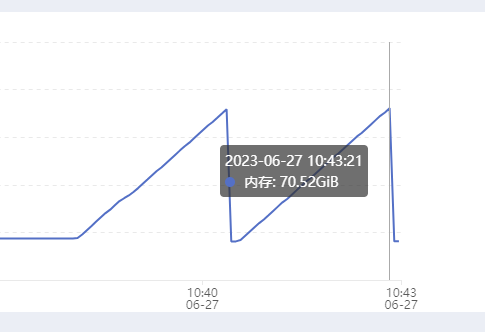
2.2 8位压缩测试 load-8bit

显存不足,无法加载model
2.3 将不适合 GPU 的权重卸载到 CPU 内存上 cpu-offloading

成功运行
- 显存
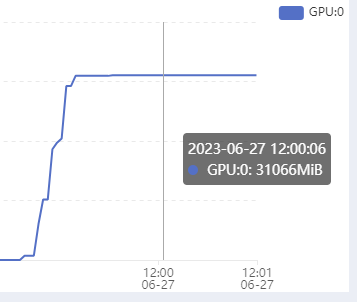
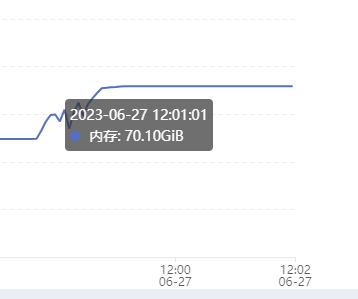
- 内存
3. 运行测试(8bit + cpu offloading)
3.1 性能占用
- GPU
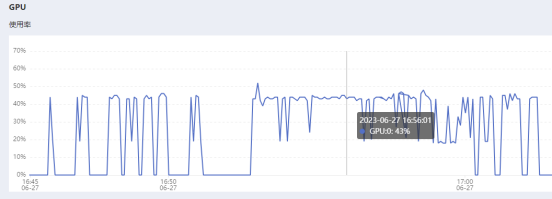
平均占用45~50%
- 显存
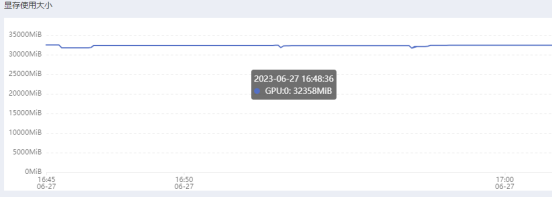
平均占用32G(拉满)
- CPU
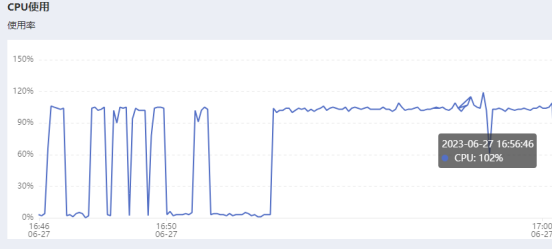
平均占用100%
- 内存
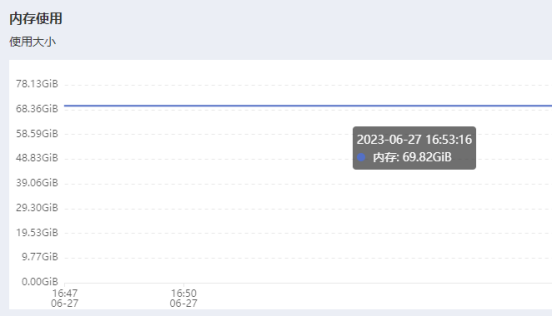
平均占用69~70G
3.2 官方issue

•需要 24G * 3 + 2 内存 •4路nvidia tesla p40

评论
暂无评论
* 登录后即可评论